Cos'è Git?
Git è il sistema di controllo delle versioni più utilizzato al mondo. Git è un progetto open source originariamente sviluppato nel 2005 da Linus Torvalds, il famoso creatore del kernel del sistema operativo Linux. Git è un esempio di DVCS (Distributed Version Control System), quindi, la copia di lavoro del codice di ogni sviluppatore è anche un repository che può contenere la cronologia completa di tutte le modifiche. In altre parole, è un sistema che tiene traccia dei cambiamenti ai file del nostro progetto col tempo. Ci permette di registrare cambiamenti al progetto e tornare indietro ad una versione specifica del file tracciati, in qualsiasi momento. Questo sistema può essere usato da molte persone per lavorare insieme in modo efficiente e collaborare su progetti di gruppo, in cui ogni sviluppatore può avere la propria versione del progetto, distribuito sul loro computer. Più tardi, queste singole versioni del progetto potranno essere unite e adattate all’interno della versione principale.
Benefici Principali
Ti consente di tenere traccia delle tue modifiche
Hai sempre uno stato che monitora esattamente quali modifiche sono state apportate in qualsiasi momento.
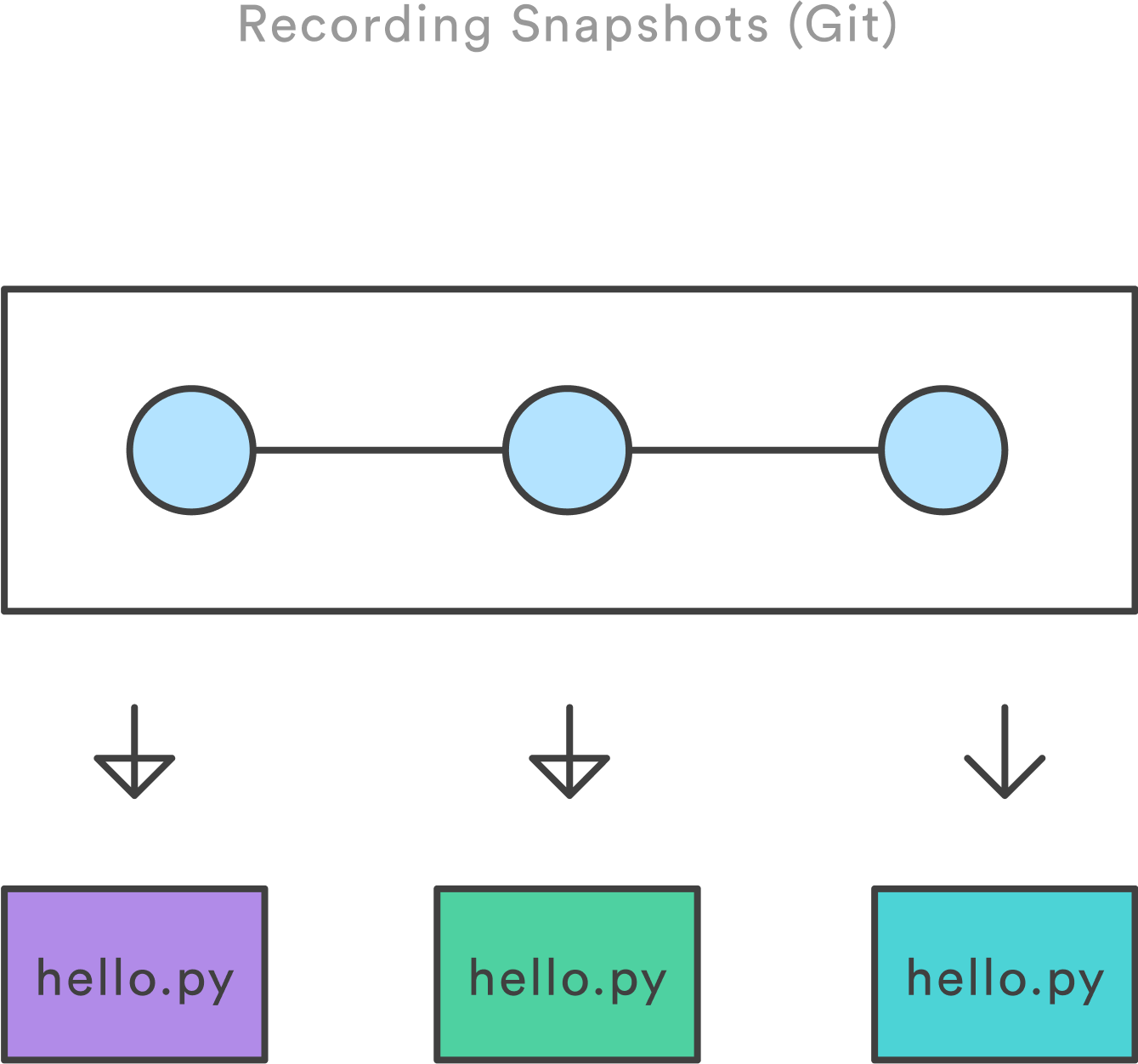
Backup storico, che usa gli “snapshots” (istantanee)
Fondamentalmente puoi mantenere una versione precedente e ripristinarla se necessario. Quindi se vengono riscontrati bug o si incasina qualcosa, è sempre possibile tornare indietro con un backup storico e annullare tali modifiche.
Team development
Consente a un team di sviluppatori di lavorare effettivamente sullo stesso codice contemporaneamente e quindi unire le loro modifiche insieme per fare progressi su un progetto.
Flessibilità del progetto
Consente di lavorare localmente su un progetto oppure Git o GitHub possono essere utilizzati come parte dei flussi DevOps.
Branching
I rami vengono creati dal progetto di base, al fine di sviluppare una nuova funzionalità, correggere un bug o semplicemente eseguire un refactoring. Impediscono agli sviluppatori di software di disturbarsi a vicenda e consentono loro di lavorare in parallelo. Una volta terminata e verificata una modifica, il ramo viene nuovamente unito al tronco.
Git per sviluppatori
Uno dei maggiori vantaggi di Git sono le sue capacità di ramificazione. A differenza dei sistemi di controllo delle versioni centralizzati, i rami Git sono economici e facili da unire. Ciò facilita il flusso di lavoro degli utenti di Git.

I rami forniscono un ambiente isolato per ogni modifica alla base del codice. Quando uno sviluppatore vuole iniziare a lavorare su qualcosa, non importa quanto grande o piccolo, crea un nuovo branch. Ciò garantisce che il branch principale (Main) contenga sempre un codice originale.
Git, essendo un sistema di controllo di versioni distribuito, invece di fare una copia della repository, ogni sviluppatore ottiene il proprio repository locale, completa con tutta la cronologia dei commit.

Avere una cronologia locale completa, rende Git veloce, poiché significa che non è necessaria una connessione di rete per creare commit, ispezionare versioni precedenti di un file o eseguire “diffs” tra i commit. Lo sviluppo distribuito semplifica inoltre la scalabilità del team di sviluppo. Se qualcuno interrompe il ramo di produzione in SVN, gli altri sviluppatori non possono archiviare le modifiche finché non vengono risolte. Con Git questo tipo di blocco non esiste. Tutti possono continuare a svolgere le proprie attività nei propri repository locali.
Richiesta di pull
Una richiesta pull è un modo per chiedere a un altro sviluppatore di unire uno dei tuoi rami nel proprio repository. Ciò non solo rende più facile per i responsabili del progetto tenere traccia delle modifiche, ma consente anche agli sviluppatori di avviare discussioni sul loro lavoro prima di integrarlo con il resto della base di codice.

Le richieste pull sono estremamente versatili, infatti, quando uno sviluppatore rimane bloccato con un problema difficile, può aprire una pull request per chiedere aiuto al resto del team. Facendo ciò, gli sviluppatori junior possono essere sicuri di non distruggere l'intero progetto trattando le richieste pull come una revisione formale del codice.
In molti ambienti, Git è diventato il sistema di controllo standard della versione previsto per i nuovi progetti.

Inoltre, Git è molto popolare tra i progetti open source. Ciò significa che è facile sfruttare librerie di terze parti e incoraggiare altri a creare il proprio codice open source.
Cos'è una repository?
Una repository è un archivio virtuale del tuo progetto. Ti consente di salvare versioni del tuo codice, a cui puoi accedere quando necessario.
Possiamo individuare due maggiori tipi di repositories:
Repository locale:
un repository isolato salvato sul tuo computer, dove puoi lavorare sulla versione locale del tuo progetto.
Repository remota:
generalmente salvato al di fuori del tuo sistema locale isolato, di solito su un server remoto. Spesso è utile per lavorare in gruppo, è il posto in cui puoi condividere il tuo codice, vedere quello di altre persone e integrarlo con il tuo e inoltre puoi effettuare un “push” delle modifiche alla repository remota.
Git init
Usa il comando git init per convertire un progetto esistente senza versione in un repository di Git.
La maggior parte degli altri comandi Git non sono disponibili in un repository noninizializzato, quindi questo è solitamente il primo comando che esegui in un nuovo progetto.
Git clone
Il comando git clone viene utilizzato principalmente per puntare a un repository esistente e creare un clone o una copia di quel repository in una nuova directory, in un'altra posizione.
Per farlo, vai su GitHub e apri una repository, quindi copia l'URL SSH.
Dopodiché esegui questo comando: git clone SSH_URL
Questo aggiunge la cartella .git e il repository remoto. Il modello di collaborazione di Git si basa sull'interazione tra repository e repository. Invece di controllare una copia funzionante nel repository centrale, puoi eseguire il push o il pull dei commit da una repository all'altra.

Git clone vs Git init
Git add
Dalla cartella del progetto, possiamo usare git add per aggiungere i nostri file nella staging area che permette di tracciarli.

Possiamo aggiungere un file specifico alla staging area con il comando git add nomeDelFile
Possiamo anche aggiungere più file. Invece di aggiungere i file individualmente, possiamo aggiungerli tutti insieme dalla cartella del progetto alla staging area: git add .
Git commit
Un commit è uno snapshot del nostro codice in un momento particolare che noi salviamo nella cronologia dei commit del nostro repository. Dopo aver aggiunto tutti i file che vogliamo tracciare alla staging area con il comando git add , siao pronti a fare un commit.
Per eseguire i commit dei file dalla staging area, usiamo il comando git commit -m "descrizione del commit"
All’interno delle virgolette dovremmo scrivere un messaggio usato per identificarlo nella cronologia dei commit. Questo messaggio dovrebbe descrivere in maniera riassuntiva i cambiamenti effettuati alla repository.
git commit --amend è un modo conveniente per modificare il commit più recente. Ti consente di modificare il commit precedente invece di creare un commit completamente nuovo. Può anche essere utilizzato per modificare semplicemente il messaggio del commit precedente senza modificarne lo snapshot, ma, la modifica non solo altera il commit più recente, lo sostituisce
git commit --amend -m "descrizione del commit "
interamente, il che significa che il commit modificato sarà una nuova entità con il proprio ref (puntatore).
Per creare un nuovo commit, dovrai ripetere il processo di aggiungere i file alla staging area e fare il commit dopo. È molto utile usare il git status per vedere quali file sono stati modificati
Git Stash
Il comando git stash archivia temporaneamente le modifiche che hai apportato alla tua copia di lavoro in modo da poter lavorare su qualcos'altro, quindi tornare indietro e applicarle nuovamente in seguito. Lo stashing è utile se devi cambiare rapidamente contesto e lavorare su altro e sei a metà di una modifica del codice o non sei ancora pronto per il commit.
La stash (scorta) è salvata in locale nel tuo repository Git quindi non verrà trasferita al server quando si esegue il push.
Puoi riapplicare le modifiche precedentemente nascoste con git stash pop
Facendo ciò le modifiche nella tua stash verranno cancellate e applicate alla working copy. Per evitare ciò, usando git stash apply, le tue modifiche verranno applicate alla working copy senza rimuoverle dalla stash.
Non sei limitato a una singola scorta. Puoi eseguire git stash più volte per creare più nascondigli, quindi utilizzarli git stash list per visualizzarli. Per impostazione predefinita, gli stash sono identificati semplicemente come "WIP" (working in progress) in cima al ramo e al commit da cui hai creato lo stash.
Dopo un po' può essere difficile ricordare cosa contiene ogni scorta, quindi per capire meglio l’argomento di ogni stash si scrive un commento che descrive quello che si è fatto
Quando si hanno liste di stash, per riapplicare una specifica stash alla working copy si esegue il solito comando git stash pop con l’aggiunta di un indice: git stsh pop stash@{indice}
Di standard, git stash pop applica la stash più recente: stash@{0}. Come si è potuto intuire, l’indice delle stash va in ordine decrescente, quindi lo stash meno recente sarà quello con l’indice più alto.
Git ignore
Per ignorare file che non vuoi che siano tracciati o aggiunti alla staging area, puoi creare un file chiamato .gitignore nella tua cartella principale del progetto. All’interno del file, puoi fare una lista di tutti i file e cartelle che sicuramente non vuoi tracciare.
Per capire come lavorare con .gitignore utilizza questo sito:
Git status
Il comando git status viene utilizzato per visualizzare lo stato della directory di lavoro e dell'area di staging.
Per capire come lavorare con .gitignore utilizza questo sito:
Ci fa vedere quali file sono stati cambiati, tracciati, etc. Possiamo aggiungere i file dei progetti non tracciati alla staging area basandoci sulle informazioni prese dal comando git status. Più tardi, git status riporterà le modifiche che abbiamo fatto ai nostri file tracciati prima di decidere se aggiungerli alla staging area di nuovo.
Git log
Per vedere tutti i commit fatti sul nostro progetto possiamo usare il comando git log
I registri mostreranno i dettagli per ogni commit, come il nome dell’autore, l’hash generato per il commit, la data e l’orario del commit e il messaggio che abbiamo fornito in precedenza. Per andare ad uno stato precedente del tuo codice del progetto, puoi usare comando git checkout {commit-ash}
Cambia {commit-hash} con l’hash per il commit specifico che vuoi visitare, il quale è in lista con il comando git log. Per andare all’ultimo commit (la versione più nuova del nostro codice di progetto), puoi scrivere il comando git checkout master
Se stai lavorando ad un progetto grande, il git log risulterà incasinato perché ci saranno molti più commit; un modo per risolvere questo problema è usare git log —oneline
Git log vs Git status
Mentre git status ti consente di ispezionare la working directory e la staging area, git log opera solo sulla cronologia dei commit.

Annullamento di commit e modifiche
Per capire bene come funziona l’annullamento in Git, bisogna pensare a esso come ad un'utilità di gestione della sequenza temporale. I commit sono snapshot di un momento o di punti di interesse lungo la timeline della cronologia di un progetto. Inoltre, è possibile gestire più timeline attraverso l'uso di branch. Quando si "annulla" in Git, di solito si torna o indietro o in un'altra timeline in cui non si sono verificati errori.
L'idea alla base di qualsiasi sistema di controllo della versione è archiviare copie "sicure" di un progetto in modo da non doversi mai preoccupare di rompere irreparabilmente la base di codice. Dopo aver creato una cronologia dei commit del progetto, puoi rivedere e rivisitare qualsiasi commit nella cronologia. Per far ciò si utilizza git log.
Ogni commit ha un hash di identificazione SHA-1 univoco (ex: 6decb6f1). Questi ID vengono
utilizzati per percorrere la timeline impegnata e rivisitare i commit. Di default, git log mostra solo i commit del branch attualmente selezionato; è possibile però che il commit che stai cercando sia su un altro ramo. Puoi visualizzare tutti i commit su tutti i branch eseguendo git log --branches .Usando invece git branch-a verrà restituito un elenco di tutti i branch conosciuti. Uno di questi, può essere registrato utilizzando git log.
Quando hai trovato il riferimento del commit al punto della cronologia(history) che desideri visitare, puoi utilizzare il comando git checkout per ispezionare il commit.
git checkout serve a "caricare" gli snapshots sul pc. Mentre lavoriamo al progetto, l’HEAD di solito punta al main o a qualche altro branch locale, ma quando si estrae un commit precedente, l’HEAD non punta più ad un branch, ma punta direttamente ad un commit.

L'estrazione di un vecchio file non sposta l’HEAD, infatti, rimane sullo stesso branch e sullo stesso commit. Puoi quindi eseguire il commit della vecchia versione del file in un nuovo snapshot come faresti con qualsiasi altra modifica. Quindi questo utilizzo di git checkout su un file serve per tornare a una vecchia versione di un singolo file.
Esempio:

Questo esempio lo utilizzerò per spiegare la differenza dei comandi che si usano di solito per l’annullamento di commit e modifiche. L’obbiettivo dell’esercizio è quello di annullare il commit 872fa7e che risulta, in un progetto ipotetico, una modifica sbagliata che vogliamo annullare.
Git rm
Per rimuovere un file dalla staging area, esegui il comando git rm --cached
Git checkout
Usando il comando git checkout possiamo controllare il commit precedente, a1e8fb5, mettendo il repository in uno stato prima che si verificasse il commit sbagliato. Il checkout di un commit specifico metterà il repository in uno stato di "detached HEAD". Ciò significa che non lavori più su nessuna branch. In uno stato “detached”, tutti i nuovi commit che esegui saranno resi “orfani” quando cambi branch in un branch stabilito. I commit orfani verranno eliminati dal Garbage Collector di Git. Per evitare che i commit orfani siano nel garbage collector, dobbiamo assicurarci di trovarci su un branch stabilito.
Dallo stato "detached HEAD", possiamo eseguire git checkout -b nuovo-branch. Questo creerà un nuovo branch chiamato "nuovo-branch" che passerà a quello stato. Il repository è ora su una nuova timeline della cronologia in cui il commit 872fa7e non esiste più. A questo punto, possiamo continuare a lavorare su questo nuovo branch in cui il commit 872fa7e non esiste più e considerarlo “undone”(annullato). Questa strategia di annullamento non è appropriata se il branch in questione si tratta del main; questo perché il main branch non può essere mai cancellato dato che è il ramo portante di tutto il progetto.
